
来源:慧荣科技
随着人工智能技术的爆发式增长,数据不仅在数量上呈现指数级飞跃,其存在形态与交互模式也发生了根本性的转变。在当今的计算架构中,数据不再仅仅是静止存放于仓库中的“货物”,而是变成了一条高速流动的“管道”。从边缘设备的实时采集,到核心数据中心的高强度训练,再到最终端的推理应用,每一个环节都对数据流转的速度提出了严苛要求。
然而,当前的计算架构面临着一种不对称的挑战:虽然GPU的算力正在以摩尔定律的速度狂飙,但作为基础设施底座的存储系统,若无法跟上数据流动的步伐,便会成为制约整体性能的瓶颈。一旦存储响应滞后,昂贵的GPU计算资源将被迫处于闲置等待状态。因此,构建一个能够匹配AI算力需求、拒绝“堵车”的高效数据存储管道,已成为释放AI潜能的关键所在。
#01痛点解析
什么在阻碍AI数据的流动?
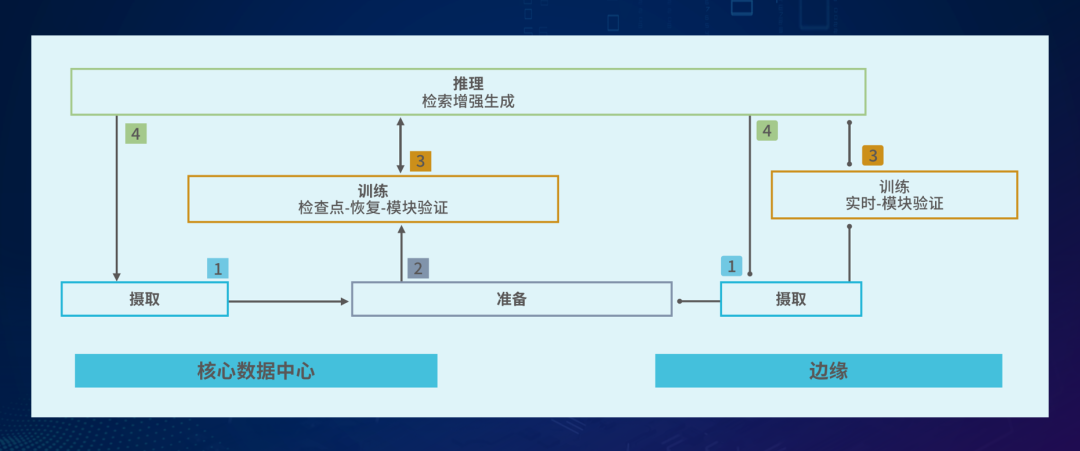
深入剖析AI的全生命周期,可以发现其工作负载具有极高的复杂性。一个完整的AI任务通常包含数据摄取(Ingestion)、数据准备(Preparation)、模型训练(Training)和模型推理(Inference)等多个阶段,而每个阶段对存储系统的读写需求截然不同:
数据摄取阶段:面临海量非结构化数据的涌入,要求存储系统具备极高的循序写入吞吐量。
模型训练阶段:GPU集群需要频繁地以极低延迟进行随机读取,同时还需要定期进行高带宽的检查点(Checkpoint)写入,以保存训练进度。
推理应用阶段:则对系统的响应速度和低延迟有着极致的追求。
在实际的数据中心环境中,上述这些任务并非孤立执行,往往是多租户、多任务并行处理。这就导致了严重的“IO混合效应”(IO Blending)。当大带宽的顺序写入(如数据清洗或检查点保存)与对延迟敏感的随机读取(如推理或训练采样)同时发生时,存储介质内部会产生剧烈的资源争夺。这种无序的竞争会导致性能抖动,显著增加延迟,进而打断GPU的流水线操作。这种由IO冲突引发的效率损耗,正是当前阻碍AI数据高效流动的主要症结。
#02技术破局
从“交通管制”到“智能收纳”
面对复杂的IO混合难题,慧荣科技通过一系列前沿的固件算法与架构创新,从物理底层到逻辑层面对SSD技术进行了重塑。
1用“交通管制”解决数据拥堵(PerformaShape)
针对多租户环境下的资源冲突问题,慧荣科技推出了专有的PerformaShape技术。
PerformaShape利用基于硬件的隔离机制和先进的QoS(服务质量)算法,能够识别不同类型的AI工作负载。它允许系统为关键任务(如实时推理或高优先级训练)预留专用带宽,相当于开辟了“专用车道”。即使在数据写入最为密集的时刻,该技术也能确保关键的读取任务不受干扰,从而在极端的混合工作负载下,依然保持存储性能的确定性和低延迟,彻底解决“嘈杂邻居”(Noisy Neighbor)带来的干扰问题。
2用“智能收纳”提升读写效率(ZNS&FDP)
为了进一步提升存储介质的利用率与寿命,慧荣科技深度应用了ZNS(区域命名空间)与FDP(灵活数据放置)技术。
传统的SSD往往像一个黑盒,主机无法控制数据在闪存上的具体落点,导致大量无效的数据搬运(即写放大,WAF)。而FDP与ZNS技术则让主机系统能够“看懂”SSD的物理布局。这就好比在这个巨大的“数据图书馆”中,实施了“智能收纳”策略,将具有相同生命周期或访问频率的数据直接放置在物理上相邻的区域。这种机制不仅大幅降低了SSD内部的写放大,显著延长了闪存(尤其是 QLC)的使用寿命,更通过减少后台垃圾回收的干扰,进一步降低了读写延迟,确保数据管道始终畅通无阻。
#03解决方案
MonTitan平台与SM8366主控芯片
上述一系列突破性技术的落地,离不开强大的硬件载体。慧荣科技打造的MonTitan PCIe Gen5 SSD开发平台,正是为AI时代量身定制的解决方案。
作为该平台的核心引擎,SM8366主控芯片集成了16通道设计,支持高速PCIe Gen5接口。它不仅能够提供高达14GB/s的顺序读取速度和超过300万IOPS的随机性能,更重要的是,它完美支持了PerformaShape、FDP、ZNS等先进特性。此外,针对AI训练对海量数据集的需求,SM8366 主控芯片支持高达128TB的单盘容量,为构建高性能、高密度、低功耗的 AI 数据中心提供了最佳基石。
在AI竞赛日益白热化的今天,存储技术的革新已成为决定算力效率的关键变量。慧荣科技致力于通过从核心数据中心到边缘设备的持续存储创新,以先进的主控芯片技术和解决方案,帮助企业构建安全、高效的数据基础设施,最大化AI时代的投资回报。











